TOC
对于 RabbitMQ 集群,虽然官方提供了 RabbitMQ 管理 UI 来监控集群状态,但是从设计上来说这种方式并不是特别方便,这里我是借助 Prometheus 并配合 Grafana 来整体监控 RabbitMQ 集群。
对于 RabbitMQ,从 3.8.0 版本开始,RabbitMQ 就内置了对 Prometheus 和 Grafana 的支持。但实质上是通过 rabbitmq_prometheus 这个插件来获取对 Prometheus 度量标准的支持,该插件是通过专用的 TCP 端口来暴露相关 RabbitMQ 指标的,默认端口是 15692。这些度量标准提供了对 RabbitMQ 节点状态和运行时的状态的支持。
这里我用的是之前已经安装并配置完成的 Prometheus 和 RabbitMQ 集群,具体信息如下:
# Prometheus 监控
host_ip: 10.10.2.192
# RabbitMQ 集群
rabbit@rabbitmq-node-1: 10.10.2.193 3.8.0
rabbit@rabbitmq-node-2: 10.10.2.194 3.8.0
rabbit@rabbitmq-node-3: 10.10.2.195 3.8.0
具有三个节点的 RabbitMQ 集群的安装配置可以参考: 3-node RabbitMQ 3.8 cluster
RabbitMQ 集群配置
修改集群名称
RabbitMQ 集群都有一个描述性的名称,这个名称一般具有某些意义,这里有一些针对集群名称的一些操作,具体如下:
查看集群名称:
➜ rabbitmq-diagnostics -q cluster_status | grep "Cluster name"
Cluster name: rabbit@rabbitmq-node-1
这里的 rabbit@rabbitmq-node-1 就是我这个集群的名称,比较草率哈
修改集群名称:
➜ rabbitmqctl -q set_cluster_name <cluster_new_name>
这里为了简单就不修改了,不影响具体的功能,只是一个名称而已。
启用 rabbitmq_prometheus 插件
接下来我们需要在集群所有节点上均启用 rabbitmq_prometheus插件,具体操作如下:
➜ rabbitmq-plugins enable rabbitmq_prometheus
具体输出内容如下,也表示该插件启用成功:
rabbitmq-plugins enable rabbitmq_prometheus
Enabling plugins on node rabbit@rabbitmq-node-1:
rabbitmq_prometheus
The following plugins have been configured:
rabbitmq_management_agent
rabbitmq_prometheus
rabbitmq_web_dispatch
Applying plugin configuration to rabbit@rabbitmq-node-1...
The following plugins have been enabled:
rabbitmq_management_agent
rabbitmq_prometheus
rabbitmq_web_dispatch
started 3 plugins.
指标校验
当 rabbitmq_prometheus 插件启用成功后,可以通过 curl 工具测试是否输出 Prometheus 需要的指标,如下所示:
➜ curl -s localhost:15692/metrics | head -n 6
# TYPE erlang_mnesia_held_locks gauge
# HELP erlang_mnesia_held_locks Number of held locks.
erlang_mnesia_held_locks 0
如上所示表示该插件可以正常暴露 RabbitMQ 集群相关指标
Prometheus 监控配置
上述过程成功输出了 Prometheus 指标数据后,接下来需要配置 Prometheus 让其监控上 RabbitMQ 集群,修改 Prometheus 配置文件,增加如下内容:
scrape_configs:
...
- job_name: 'rabbitmq_nodes'
static_configs:
- targets: ['10.10.2.193:15692','10.10.2.194:15692','10.10.2.195:15692']
...
修改完成后重启 Prometheus 服务即可。
可以看到此时 Prometheus 已经将 MQ 集群节点纳入监控:
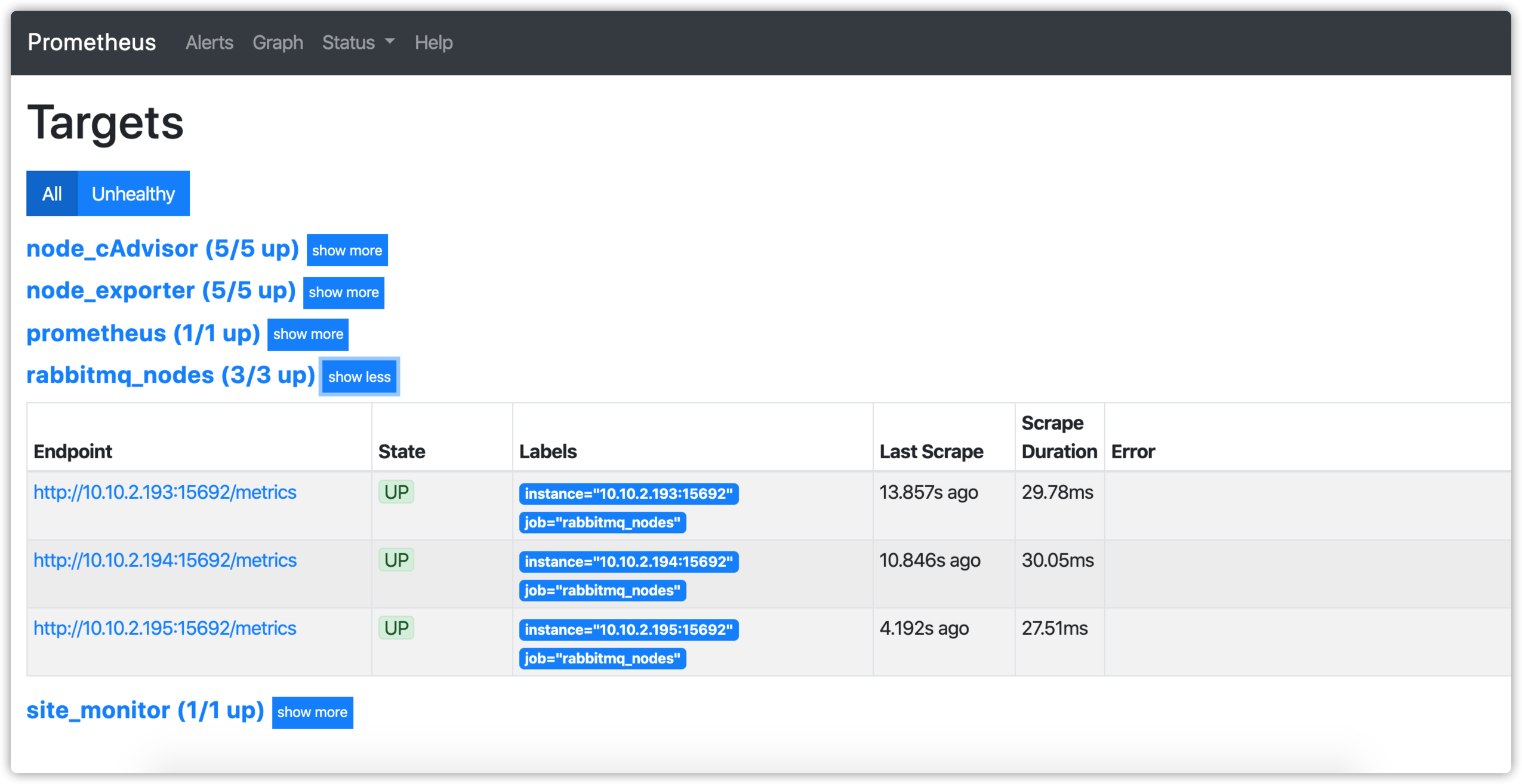
默认情况下 Prometheus 每 60s 拉取一次指标,RabbitMQ 也会定期更新相关指标,默认为 5000ms,相关参数是 collect_statistics_interval 可以根据需要对其进行更改。
对于生产环境建议 Prometheus 拉取时间设置为 15s, RabbitMQ 更新指标的时间间隔最小值设置为 10000(10s)即 collect_statistics_interval 参数设置为 10000。
Grafana 仪表盘设置
Prometheus 监控配置完成后,我们就可以导入 Grafana 的仪表盘了,RabbitMQ 官方有提供相关仪表盘文件,我们直接导入即可,具体项目地址rabbitmq-prometheus这里为了方便我只是导入了 RabbitMQ-Overview.json,其他正常导入即可。
导入成功后就可以通过 Grafana 查看该 RabbitMQ 集群的相关信息了,具体信息可以参考下图:
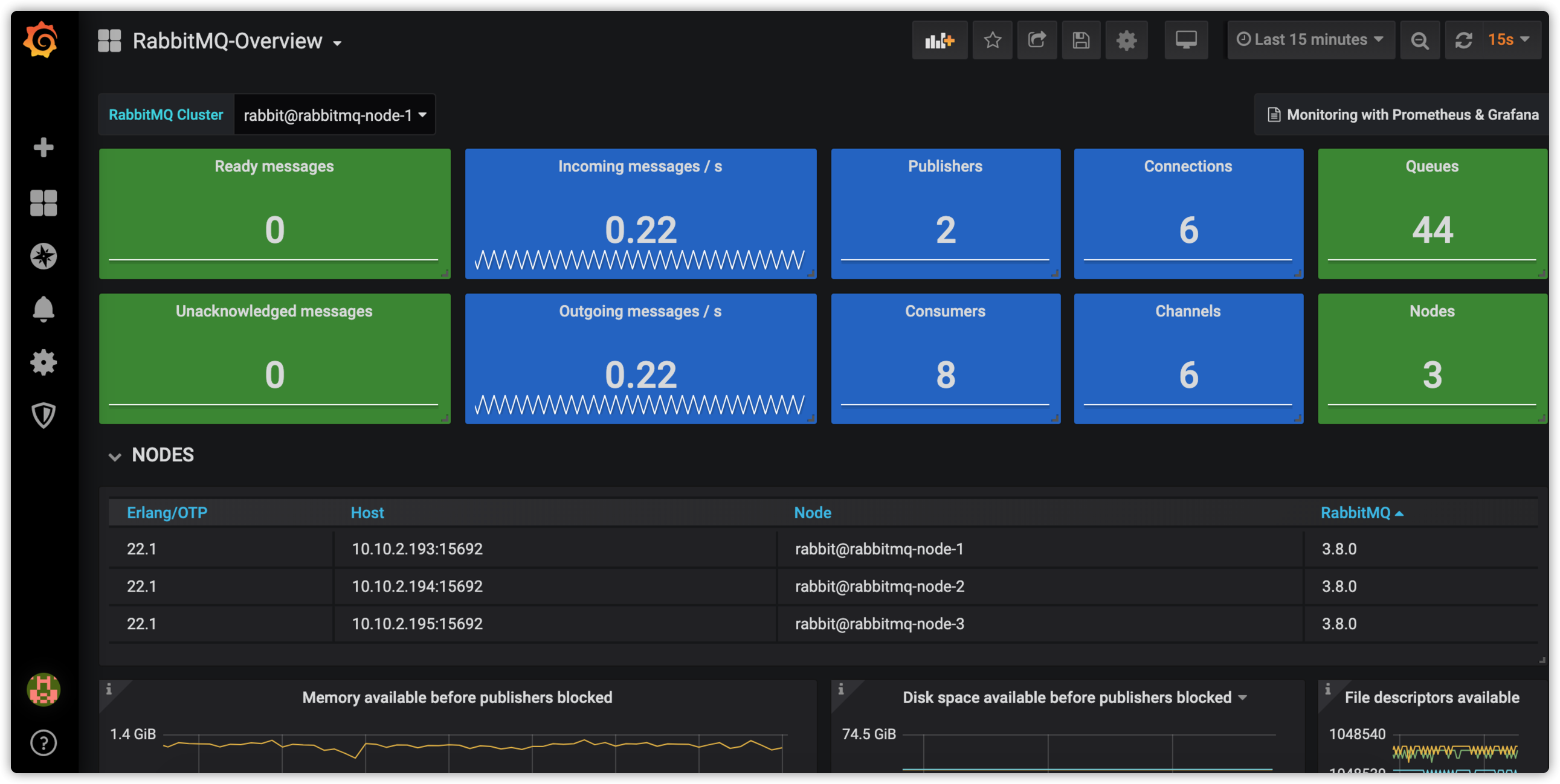
需要注意的是某些仪表盘可能导入后没有数据展示,这个时候我们可以根据具体报错信息对相关仪表盘做相应修改。
上述内容都是基于 3.8 版本及其以后的版本,对于 3.8 版本之前的版本可以使用单独的插件 prometheus_rabbitmq_exporter来暴露指标数据。该插件借助的是 RabbitMQ HTTP API来实现的。
参考链接
- Monitoring — RabbitMQ
- Cluster Formation and Peer Discovery — RabbitMQ
- Monitoring with Prometheus & Grafana — RabbitMQ
comments powered by Disqus